We attended the Animal Rights Forum 2024 at Melbourne Town Hall over the weekend of 24th and 25th February. This was the first in-person forum since the 2019 event that we also attended in Melbourne and it was great to see the event sold out on its return with over 300 attendees!
TL;DR
I appreciate that most of my readers are looking to me to provide testing/IT content (rather than veganism or animal rights material), so the only tech-related talk at this Forum was around AI, surprise surprise! Thankfully, it was a great session and a neat application of AI and automation in the not-for-profit sector by Kyle Behrend of NFPS.AI. I immediately saw how this niche use of these technologies can be of huge benefit to not-for-profits to free up their valuable and limited resources. More details of Kyle’s talk can be found under the Sunday section of this blog post.
Read on if you have any interest in the event in more detail.
There were many awesome organizations in the animal rights space represented at the Forum and the two days were packed with track sessions, representing incredible value for around $100 (a far cry from the cost of many tech conferences!).
Saturday
We missed the opening sessions on Saturday while travelling up to Melbourne and I kicked off the day by attending author MC Ronen‘s talk, “How I use my passion for writing to create a better future for animals (and humans!) And what you can learn from it” MC’s talk was interesting and her use of fiction to spread an animal rights message is novel (no pun intended!). It made me think about my own passion for writing (both in this blog and elsewhere) and how I can put it to use in this area. Not long into MC’s talk, the Forum was sadly interrupted by pro-Palestine protesters who had issue with some of MC’s public commentary on this subject. The protesters were very vocal and physically abusive to volunteers and venue security, making for a very uncomfortable ten minutes or so before the police arrived. The volunteers need to be more prepared for disruptions – especially as the event is likely to be the target of animal agriculture interests one day – so hopefully the training they need is offered before the next forum. (The minimal Town Hall security staff also seemed very unprepared, which was more surprising.)
In the same timeslot, my wife enjoyed a remote presentation by well-known US lawyer/activist Wayne Hsiung (from The Simple Heart) talking on “Making repression backfire”. Well-known from his work with Direct Action Everywhere and the open rescue movement, it was good to hear about his latest developments and his stints in prison don’t seem to have weakened his resolve to fight for the animals!
The brief lunch break (just 45 minutes) didn’t give us much time but trusty Gopals was just across the road and fed us well as always, before we quickly made our way back to the Town Hall to commence the afternoon sessions at 1pm. The protesters had gathered en masse outside the Town Hall so we had to be escorted in and out of the building by police – a bizarre turn of events for a gathering with such peaceful motivations!
We both opted for the same session to open the afternoon, with Dean Rees-Evans (from Three Principles Training and Consultancy) on “Accessing a peaceful mind in the face of animal suffering” Dean is a psychological wellbeing practitioner and his messaging around mindfulness and its benefits in dealing with the realities of animal suffering we witness within the animal rights movement (and, of course, in all aspects of daily life where animals are exploited all around us) was OK, if a little incoherent. Many in the audience seemed to find his talk more confusing than helpful and their basic questions tended not to receive actionable answers. Dean generally offers longer workshops and it felt like he struggled to distill his message with useful takeaways into such a short talk.
We went our separate ways for the next session. My wife opted for Alex Vince (from Animal Liberation NSW) talking about “Poisons and Pesticides: An Animal Welfare Crisis”, while I attended a remote presentation by Jenna Riedi (from Faunalytics, US) on “Using research and data in animal advocacy”. Alex is very vocal in the movement to ban the awful 1080 poison in Australia (noting it’s been banned in many countries for many years) and his talk resonated well with his audience. I’d hoped to learn more about the detail of some of Faunalytics’ work as I was already familiar with the organisation and its approach. The talk was more of an introduction to the organisation, though, so I didn’t get too much out of it (but I still recommend their site as a great resource for data around so many different aspects of the movement).
We both then enjoyed Sandra Kyle talking on “An Extraordinary Time To Be Living Through – My Story Arc”. An older activist, Sandra told her story beautifully, reading eloquently and gently from a script (no slide deck here!) while also showing her obvious passion and continuing desire to grow old disgracefully! This simple talk was a highlight of the Forum for us.
A short afternoon tea break preceded the final talks of the day and we both went to the same set of group reviews, featuring Vegan Australia (represented by their CEO, Dr Heidi Nicholl), The Captain Paul Watson Foundation (represented by Haans Siver) and the Coalition for the Protection of Greyhounds. It was good to hear the new Vegan Australia CEO talking about their current initiatives and Haans did a great job of introducing the Paul Watson Foundation (founded as a result of Paul Watson’s departure from Sea Shepherd, an organisation we continue to strongly support). It was sad to hear about the continuing plight of greyhounds in the Australian racing industry but also inspiring to know that there are so many passionate activists helping to hold the evil protagonists to account (given that the government and regulators seem to be unable or unwilling to do so).
We caught the introduction to the Animal Justice Awards but unfortunately couldn’t stay for the award announcements as we needed to cross town to make our ferry back home.
Sunday
We again couldn’t make it to the Town Hall for the first sessions on Sunday, so we decided to aim for the first session after morning tea, giving us enough time to pop into our old favourite, Union Kiosk, for a morning coffee and cake. The little café was very busy with many others from the Forum there too.
We opted for different sessions to kick off the day, with my wife attending Matthew Lynch‘s talk on “Cancel Culture – An Open Forum”, while I headed to see Kyle Behrend (from NFPS.AI) and his talk on “The Power of AI & Automations”. Matthew’s talk was timely given the narrative around so many topics in Australia currently and his experience working with initiatives such as Dominion and the Farm Transparency Project made his insights very powerful.
I didn’t expect to see an AI-related talk on the programme for this Forum, despite AI chatter infiltrating everywhere I look at the moment. We’ve known Kyle for a long time through his work with Edgar’s Mission, a farm animal sanctuary we’ve visited and financially support on an ongoing basis. After leaving the mission, Kyle set up NFPS.AI and works with not-for-profit organisations to help them leverage AI and automation technologies. I wasn’t sure what to expect from this talk, given so much of the hype and nonsense spouted by so-called AI experts. Thankfully Kyle presented a very pragmatic approach to leveraging AI to help often time- and resource-poor not-for-profit organisations. He presented some interesting case studies, including one around emails where automation was used to categorise incoming emails based on their content, stashing them in different folders and then generating draft replies using AI ready for review. This process was helping to save the NFP many hours of basic email processing, freeing up valuable time for their resources to focus on more value-adding activities for their organisation. This is a very niche use of AI and Kyle is passionate about the sector and technology, so I wish him well (and have offered to help).
In the brief lunch break, we quickly headed back to Union Kiosk and managed to order and get a table before the masses arrived from the Forum. A tasty jaffle and another nice coffee with the good vibes of the friendly crowd made for an enjoyable break.
For the first session of the afternoon, we again split up, with my wife opting for Abigail Boyd MP (from The Australian Greens) with “Animal Cruelty Under Capitalism” while I went to Paul Bevan‘s (from Magic Valley) talk on “Cultivated Meat – The Future of Food”. Abigail was impressive & passionate, especially for a politician, and illustrated by example just how much of our current economic system sadly has animal exploitation as its foundation. Meanwhile, Paul Bevan did an excellent job of explaining how his company, Magic Valley, is proceeding towards production with its first range of cultivated meats (including the world’s first cultivated lamb, very Aussie!). This is an interesting space and controversial with vegans due to its use of animal cells but Paul did a good job of explaining how his (patent-pending) process works and fielded a very broad range of questions very well. Paul is certainly an impressive CEO with a passion for removing the need to kill animals for those who still want to eat “meat”.
The next session saw us both with Athena (from Animal-Free Science Advocacy) on “The Power of Story: Reframing False Narratives in Animal Exploitation Industries” (my wife was meant to attend a talk from a vegan interior designer in this timeslot, but it was cancelled). The message of this talk was excellent in explaining how to turn the narrative around from the way the animal exploitation industries would like to talk about things to a more accurate story from which to expose their obvious cruelty. Given Athena’s role in marketing, the delivery of the presentation surprisingly let down the message a little, but the content was still excellent.
Next up, my wife headed to Gary Hall (from Sheep Advocate Australia) and his talk “Sheep Crisis”, while I went to Kimberley Oxley (from Animals Australia) with “The C Words: Using Social Media to drive change for animals through compassion, connection and content”. Gary operates a sheep rescue close to where we live and his passion in advocating for sheep was palpable (as was his frustration with the slow progress to achieve even small improvements in their lives in the industry). As supporters of Animals Australia for many years, it was great to hear such an excellent presentation from Kimberley Oxley. The material was targeted perfectly for this audience and delivered very well, a highly impactful talk from one of the most professional animal rights organisations in the world (I’d encourage you to check out the quality of their content if you’re unfamiliar with their work).
Afternoon tea was a catered affair with two nice choices of vegan cakes as well as vegan samosas, before the final session kicked off. These final sessions were all group reviews and we split up for coverage, so my wife saw presentations by World Animal Protection, GREY2K USA Worldwide (represented by Carey M. Theil) and Action for Dolphins (represented by Hannah Tait), while I got Animals Australia (Kim Oxley again) and the Animal Justice Party (the Australian Alliance for Animals was also meant to present but didn’t). Hannah was particularly impressive, a young activist leading an organisation doing great work for dolphins. Kim Oxley did a good job again outlining the current priorities for Animals Australia and the Animal Justice Party (AJP) representatives did a decent job of introducing the party and its values. (Disclosure: we were both paid up members of the AJP until they sided with the Labor government in Victoria during the pandemic, unbelievably supporting policies that infringed on the most basic human rights and certainly not in alignment with the claimed values of the party.)
All too soon, it was time for everyone to come back together for a short wrap-up, thanking the volunteers and so on.
It was a great event and kudos to the volunteers for getting it up and running again in difficult circumstances. There was a broad range of organisations and diversity in the speaker line-up (again in contrast to many tech conferences).
We both came away from the Forum feeling inspired and keen to help out some of the organisations (as well as continuing our financial support for some of them).
Another opportunity to work with McGill University undergraduate students came my way when Rob Sabourin again asked me to be interviewed during one of his sessions of the ECSE-428-001 – Software Engineering Practice course for his Winter 2024 cohort.
My latest interview was different, in that the focus was on the Scaled Agile Framework (SAFe) based on my recent experience of being involved in a large project using this framework. We discussed the general ideas around SAFe as well as talking specifically about where and how testing fits in. While there are many criticisms of this framework from the agile community, we discussed some of the beneficial aspects of it in the context of very large programs of work.
It was great to have so much engagement from the students physically in the room with Rob and I hope that by hearing about real-life experiences they get a more well-rounded perspective of not only the theory but also the practice of software engineering.
I’m always willing to share my knowledge and experience, it’s very rewarding personally as well as providing an opportunity to give back – I’ve had a lot of help and encouragement along my career journey (including from Rob himself) and remain incredibly grateful for it.
I missed the announcement of the publication of the 2023-24 World Quality Report so I’m catching up here to maintain my record of reviewing this annual epic from Capgemini (I reviewed the 2018/19, 2020/21 and 2022/23 reports in previous blog posts).
I’ve taken a similar approach to reviewing this year’s effort, comparing and contrasting it with the previous reports where appropriate. This review is a lengthy post, but I’m still doing you a favour even if you read this in its entirety compared to the 96 pages of the actual report!
TL;DR
The 15th edition of the “World Quality Report” is the fourth I’ve reviewed in detail and this is the thickest one yet (in every sense?).
As expected, AI is front and centre this year which is somewhat ironic given AI & ML barely got a mention in last year’s report. The hype is real and some of the claims made by respondents around their use and expected benefits of AI strike me as being very optimistic indeed. Their faith in the accuracy of their training data is particularly concerning.
Realizing value from automation clearly remains a huge challenge and I found the data around automation in this year’s report more depressing than usual. I got the feeling that AI is seen as the silver bullet in solving automation woes and I think a lot of organizations are about to be very disappointed.
It would have been nice to see some questions around human testing to help us to understand what’s going in these large organizations but, alas, there was nothing in the report to enlighten us in this area. The prevalence of Testing Centres of Excellence (CoEs) is another hot topic, despite previous reports suggesting that such CoEs were becoming less common as the movement towards agility marched on.
There continue to be many problems with this report – from the sources of its data, to the presentation of findings, and through to the conclusions drawn from the data. The lack of responses from smaller organizations mean that the results remain heavily skewed to very large corporate environments, which perhaps goes some way to explaining why my lived reality working with organizations to improve their testing and quality practices is quite different to that described in this report.
“Quality Engineering” is not clearly delineated from testing, with the concepts often being used interchangeably – this is confusing at best and potentially misleading.
The focus areas of the report changed almost completely, from “six pillars of QE” last year to eight (largely different) areas this year, making comparisons from one report to the next difficult or impossible. The sample set of organizations is the same as last year in the interests of year-on-year comparison, so why change the focus areas making the value of any such comparisons highly questionable? Is this a deliberate ploy or just poor study design?
Unlike the content of these reports, my advice remains steadfast – don’t believe the hype, do your own critical thinking and don’t take the conclusions from such surveys and reports at face value. While I think it’s worth keeping an interested eye on trends in our industry, don’t get too attached to them – the important ones will surface and then you can consider them more deeply. Instead, focus on building excellent foundations in the craft of testing that will serve you well no matter what the technology du jour happens to be.
The survey (pages 87-91)
This year’s report runs to 96 pages, the longest since I’ve been reviewing them (up from a mere 80 pages last year). I again looked at the “About the study” section of the report first as it’s important to get a picture of where the data came from to build the report and support its recommendations and conclusions.
The survey size was again 1750, the same number as for the 2022/23 report.
The organizations taking part were again all of over 1000 employees, with the largest number (35% of responses) coming from organizations of over 10,000 employees. The response breakdown by organizational size was the same as that of the previous three reports, with the same organizations contributing every time. While this makes cross-report comparisons perhaps more valid, the lack of input from smaller organizations unfortunately continues and inevitably means that the report is heavily biased & unrepresentative of the testing industry as a whole.
While responses came from 32 countries (as per the 2022/23 report), they were heavily skewed to North America and Western Europe, with the US alone contributing 16% and then France with 9%. Industry sector spread was similar to past reports, with “Hi-Tech” (19%), “Financial Services” (15%) and “Public Sector/Government” (11%) topping the list.
The types of people who provided survey responses this year was also very similar to previous reports, with CIOs at the top (24% again), followed by QA Testing Managers and IT Directors. These three roles comprised over half (59%) of all responses.
Introduction (pages 4-5)
The introduction is the usual jargon-laden opening to the report, saying little of any value. But, there’s no surprise when it comes to the focus of this year’s epic:
…the emergence of a true game changer in the field of software and quality engineering: Generative AI adoption to augment our engineering skills, accelerated like never before. The lack of focus on quality seen in the last few years is becoming more visible now and has brought back the emphasis on the Hybrid Testing Center of Excellence (TCoE) model, indicating somewhat of a reversal trend.
Do the survey’s findings reflect the game-changing nature of generative AI around quality engineering? What’s with the “lack of focus on quality seen in the last few years” when previous reports have been glowing about QE and its importance in the last couple of years? And what exactly is a “Hybrid Testing Center of Excellence”? Let’s delve in to find out.
Executive Summary (pages 6-7)
While the Executive Summary is – as you’d expect – a fairly high level summary of the report’s findings, a couple of points are worth highlighting from it. Firstly:
…almost all organizations have transitioned from conventional testing to agile quality management. Evidently, they understand the necessity of adapting to the fast-paced digital world. An agile quality culture is permeating organizations, albeit often at an individual level rather than at a holistic program level. Many organizations are adopting a hybrid mode of Agile. In fact, 70% of organizations still see value in having a traditional Testing Center of Excellence (TCoE), indicating somewhat of a reversal trend.
I’m intrigued by what the authors mean by “conventional testing” and “agile quality management”, as well as the fact that the majority of organizations still adopt a “traditional” TCoE. Secondly:
What is clear is the extended knowledge and skills that are required from the QE experts who operate in agile teams. Coding skills in particular (C#, Java, SQL, Python), and business-driven development (BDD) and test-driven development (TDD) competencies, are in demand.
The idea that “QE experts” need coding skills and competency in BDD and TDD strikes me as unrealistic. I’m not sure whether the authors are referring to expert testers with some development skills, expert developers with some testing skills or some superhuman combination of tester, developer and BA (remembering that, of course, BDD is neither a development or testing skill, per se).
With all the “game-changing” talk around AI, there’s a nod to reality:
A significant percentage (31%) remains skeptical about the value of AI in QA, emphasizing the importance of an incremental approach.
Key recommendations (pages 8-9)
The “six pillars of QE” from the last report (viz. “Agile quality orchestration”, “Quality automation”, “Quality infrastructure testing and provisioning”, “Test data provisioning and data validation”, “The right quality indicators” and “Increasing skill levels”) no longer warrant a mention, with this year’s recommendations being in these eight areas instead:
Business assurance
Agile quality management
QE lifecycle automation
AI (the future of QE)
Quality ecosystem
Digital core reliability
Intelligent product testing
Quality & sustainability
The recommendations are generally of the cookie cutter variety and could have been made regardless of the survey results in many cases. A couple of them stood out, though. Firstly, under “Digital core reliability”:
Use newer approaches like test isolation, contract testing etc., to drive more segmentation and higher automated test execution.
The idea that test isolation and contract testing are leading edge approaches in the automation space is indicative of how far behind many large organizations must be. Secondly, under “Intelligent product testing”:
Invest in AI solutions for test prioritization and test case selection to drive maximum value from intelligent testing.
I was wondering what “intelligent product testing” was referring to, so maybe the authors are suggesting a delegation of the intelligence aspect of testing to AI? I’m aware of a number of tools that claim to prioritize tests and make selections from a library of such test cases. But I’m also aware that good test prioritization relies on a lot of contextual inputs, so I’m dubious about any AI’s ability to do this “to drive maximum value” from (intelligent) testing.”
Current trends in Quality Engineering & Testing (p11-59)
Exactly half of the report is focused on current trends, broken down into the eight areas detailed in the previous section. Some of the most revealing content is to be found in this part of the report. I’ve broken down my analysis into the same sections as the report. Strap yourself in.
Business assurance
This area was not part of the previous year’s report. There’s something of a definition of what “business assurance” is, even if I don’t feel much wiser based on it:
Business assurance encompasses a systematic approach to determining business risks and focusing on what really matters the most. It consists of a comprehensive plan, methodologies, and approaches to ensure that business operation processes and outcomes are aligned with business standards and objectives.
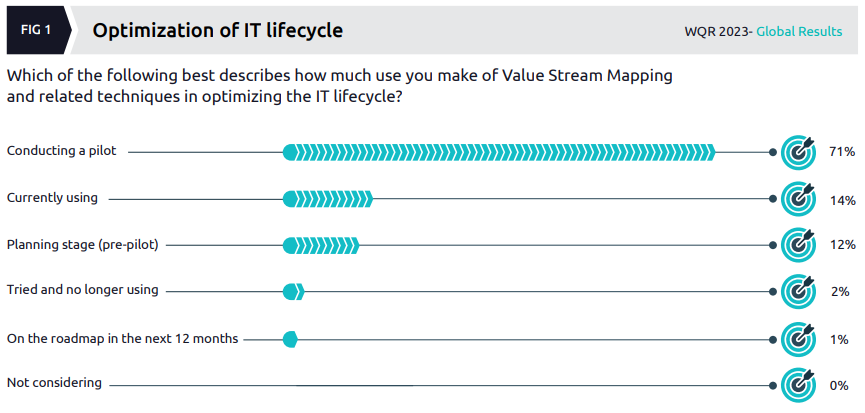
One point of focus in this section is value stream mapping (which featured in the previous report) but the authors’ conclusions about its widespread adoption appear at odds with the data:
Many organizations are running pilots apparently, but their statement that “Many businesses are now shifting from mere output to a results-driven mindset with value stream mapping (VSM)” seems to go too far.
Moving on to how QE is involved in “Business Assurance testing” (which is not defined and I’m unclear as to what it actually is):
This data was from a small sample (314 of the 1750 respondents) and their conclusion that “both business stakeholders and testers are working together during the UAT process to drive value” (from the second bar) is hardly a revelation.
I remain unclear why this area is included in this report as it doesn’t seem related to quality or testing in a strong way. The first recommendation in this section of the report is “Leverage the testing function to deliver business outcomes” – isn’t this what good testing always helps us to do?
Agile quality management
This area wasn’t in the previous year’s report (the closest subject matter was under “Quality Orchestration in Agile Enterprises”) and the authors remind us that “last year, we noticed a paradigm shift in AQM [Agile Quality Management] through the emphasis placed on embracing agile principles rather than merely implementing agile methodologies”. The opening paragraph of this section sets the scene, sigh (emphasis is mine):
The concept of agile organizations has been a part of boardroom conversation over the past decade. Businesses continue to pursue the goal of remaining relevant in volatile, uncertain, complex, and ambivalent environments. Over time, this concept has evolved into much more than a mere development methodology. It has become a way of thinking and a mindset that emphasizes continuous improvement, adaptability, and customer-centricity. This evolution is clearly represented in the trends shaping agile quality management (AQM) practices today.
I’m going to assume “ambivalent” is a typo (or ChatGPT error). Much more worrisome to me is the idea that agile has evolved from being a development methodology to “a way of thinking and a mindset that emphasizes continuous improvement, adaptability, and customer-centricity” – this is exactly the opposite of what I’ve seen! The great promise shown by the early agilists has been hijacked, certified, confused, process-ized, packaged and watered down, moving away from being a way of thinking to a commodity process/methodology. Either the authors’ knowledge of the history of the agile movement is lacking or they’re confused (or both). Having said that, if they genuinely have evidence that there’s a move away from “agile as methodology” (aka “agile by numbers”) to “agile as mindset”, then I think that would be a positive thing – but I failed to spot any such evidence from the data they share.
The first data looks at how QE is organized to support agile projects, with a whopping 70% still relying on a “Traditional Testing Center of Excellence” and essentially all the rest using “product aligned QE” (which I think basically means having QE folks embedded with the agile teams).
Turning to skills:
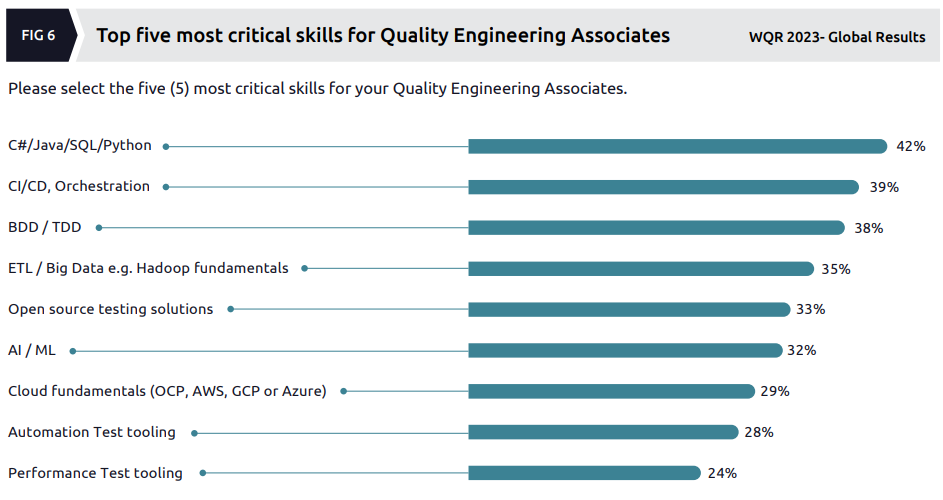
Worryingly, there is no mention here of actual testing skills, but the authors remark:
Organizations are now prioritizing development skills over traditional testing skills as the most critical skills for quality engineers. Development-focused skills like C#/Java/SQL/Python and CI/CD are all ranked in the top 5, while traditional testing skills like automation and performance tooling ranked at the bottom of the results.
Looking at this skills data, they also say:
We feel this is in alignment with the industry’s continued focus on speed to market; as quality engineers continue to adopt more of a developer mindset, their ability to introduce automation earlier in the lifecycle increases as is their ability to troubleshoot and even remediate defects on a limited basis.
I find the lack of any commentary around human testing skills (outside of coding, automation, DevOps, etc.) deeply concerning. These skills are not made redundant by agile teams/”methodologies” and the lack of humans experiencing software before it’s released is not a trend that’s improving quality, in my opinion.
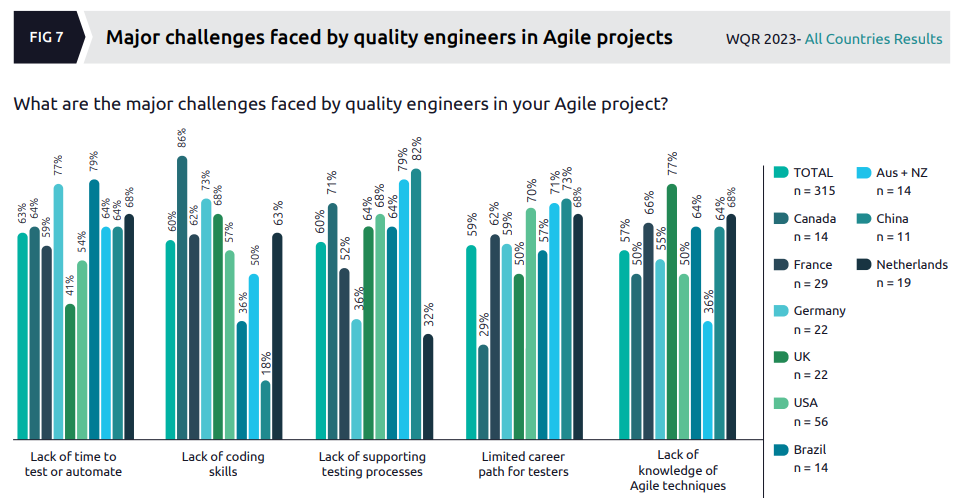
Turning to the challenges faced by quality engineers in Agile projects:
This is a truly awful presentation of the data, the lack of contrast in the colours used on the various bars makes it almost unreadable. The authors highlight one data point, the 77% of UK organizations for which “lack of knowledge of Agile techniques” was the most common challenge, saying:
This could indicate the speed at which these organizations moved into a product-aligned QE model while still trying to utilize their traditional testers.
They slip in and out of the use of terminology such as “Agile techniques” throughout the report (which is unhelpful) and they appear to be claiming that “traditional testers” moving into an Agile “product-aligned QE model” have a lack of knowledge – maybe they’re referring to good human testers being asked to become (QE) developers, in which case this lack of knowledge is to be expected.
The following text directly contradicts the previous data on the very high prevalence of “traditional” testing CoEs:
Many quality engineering organizations predicted the evolution and took a more proactive stance by shifting from a traditional ‘Testing Center of Excellence’ approach to a product-based quality engineering setup; however, most organizations are still in the process of truly integrating their quality engineering teams into an agile-centric model. As shown in the diagram… only 4% of respondents report that more than 50% of their quality engineering teams are operating in a more agile-centric pod-based model.
In closing out this section, the authors say (emphasis is mine):
…quality engineering teams are asked to take on a more development-focused persona and build utilities for the rest of the organization to leverage rather than focusing solely on safeguarding quality. The evolution of agile practices, the integration of AI and ML, and the synergy between DevOps and agile are transforming quality engineering in infinitely futuristic ways. The question is, when will organizations embrace these changes en-masse, adopt proactive strategies, and make them a norm? Next year’s report will probably unveil the answer.
I find it highly unlikely that the answer to this question will be revealed in the next report, as such questions have rarely – if ever – been answered in the past. Given how difficult it’s been for large organizations to move towards agile ways of working (despite 20+ years of trying), I’d suggest that en masse movement towards QE is unlikely to eventuate before the next big thing distracts these trend followers from realizing whatever benefits the QE model was designed to bring.
QE lifecycle automation
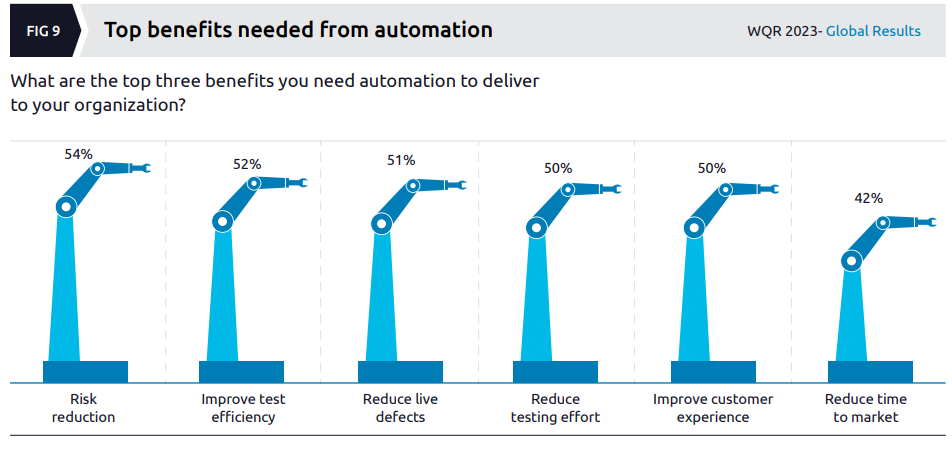
This section of the report is on all things automation, now curiously being referred to as “QE lifecycle automation”. It kicks off with the benefits the respondents are looking for from automation:
I’ll make no comment on these expectations apart from mentioning that my own experience of implementing many automation initiatives hasn’t generally seen “reduced testing effort” or “improved test efficiency” (though I’m not sure what they mean by that here).
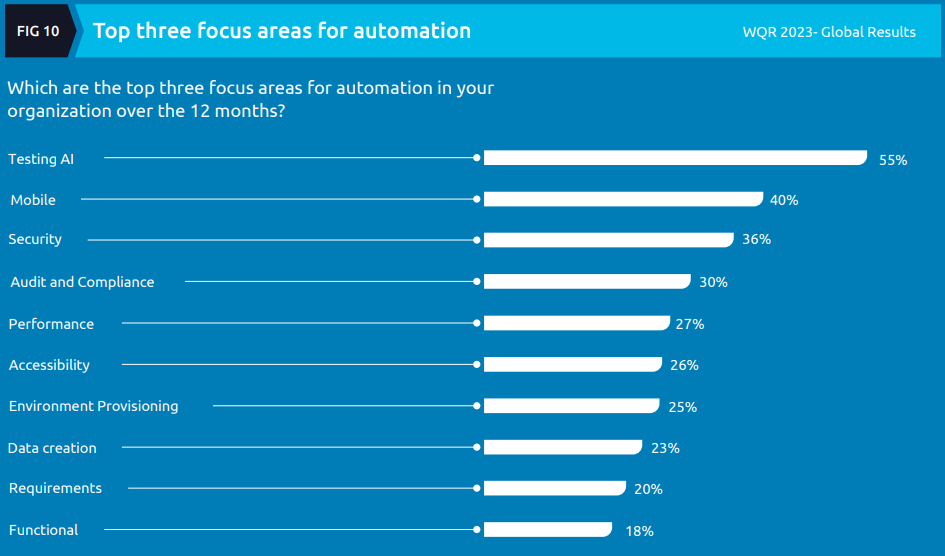
Moving into where organizations intend to focus their automation efforts in the coming year:
The authors say:
We were expecting AI to steal the limelight this year since it is the buzzword in the boardroom these days. We think that AI is the new tide that needs to be ridden with caution, which means quality engineering and testing (QE&T) teams need to understand how AI-based tools work for them, how they can do their jobs better, and bring better outcomes for their customers.
More than 50% of the respondents were eager to see testing AI with automation, which is well ahead of the other top focus areas like security and mobile.
Interestingly, we found that functional (18% of respondents) and requirements (20% of respondents) automation were of the least focus for organizations, presumably because of the challenges in automating and regular updating involved in these areas. Perhaps, this is an area where we can expect to see AI tools becoming a key part of automation toolkits.
Surprise surprise, it’s all about AI! It’s time to ride the tide of AI, folks. What does “Testing AI” mean? Is it testing systems that have some aspect of AI within them or using AI to assist with testing? Whatever it is, it’s the top priority apparently.
I also don’t understand what “Functional” means and how other automation focus areas are related to it or not. For example, if I implement a UI-driven test on a mobile device using automation, does that come under “Functional” or “Mobile” (or both). It’s hard for me to fathom how respondents answer such questions without understanding these distinctions.
The last part of the quote above is illustrative of the state of our industry – building robust and maintainable automation is just too hard, so we’ll deprioritize that and get distracted by this shiny AI thing instead.
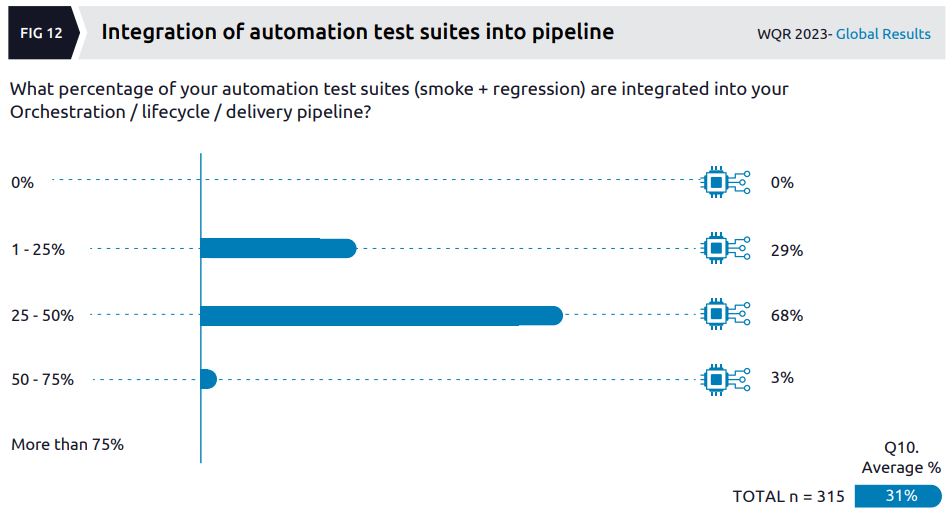
The data around integration of automated tests into pipelines makes for shocking reading:
The authors note:
Overall, the survey revealed that only 3% of respondents’ organizations have more than half of their suites integrated which may be due to diminishing returns or lack of QE access to orchestration instances. This comes as a surprise since most of the organizations now have some automated test suites integrated into their pipelines for smoke and regression testing.
I agree that this low percentage of organizations actually getting their automated test suites into pipelines is surprising! Maybe they shouldn’t be so worried about trying to make use of AI, but rather to actually make use of what they already have in a more meaningful and efficient way. The response to the next question “What are the most impactful challenges preventing your Quality Engineering organization from integrating into the DevOps/DevSecOps pipeline?” revealed that a whopping 58% (the top answer) said “Quality Engineering team doesn’t 58% have access to enterprise CI instance”, I rest my case. With no sense of irony about the report’s findings more generally, the authors say:
What was worth noting was that the more senior respondents (those furthest from the actual automation) reported higher levels of integration than those solely responsible for the work
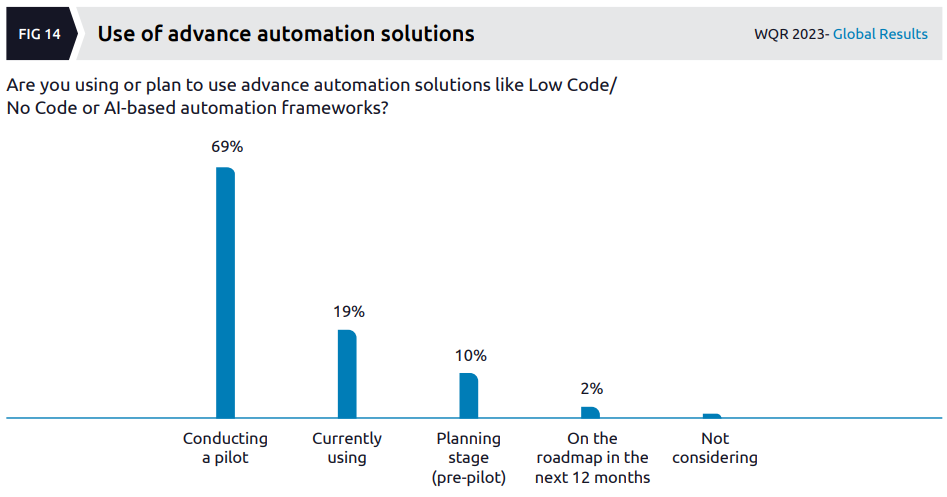
The much vaunted dominance of low/no code & AI automation solutions is blown away by this data, with not much going on outside of pilots:
The data in this section of the report, as per similar sections in previous reports, only goes to show how difficult it is for large organizations to successfully realize benefits from automation. Maybe “AI” will solve this problem, but I very much doubt it as the problems are generally not around the technology/tools/toys.
AI (the future of QE)
With AI being such a strong focus of this year’s report, this section is where we get into the more detailed data. Firstly, it’s no surprise that organizations see AI as the next big thing in achieving “higher productivity”:
Looking at this data, it’s all about speed with any consideration around improving quality coming well down the list (“lesser defects” – which should be “fewer defects” of course – coming last on this list). Expressing their surprise at this lack of focus on using AI to reduce defects, the authors say (emphasis is mine):
With Agile and DevOps practices being adopted across organizations, there is more continuous testing with multiple philosophies like “fail fast” and “perpetual beta” increasing the tolerance for defects being found, as long as they can be fixed quickly and efficiently.
I find the response around training data in this question quite disturbing:
The authors are quite bullish on this, saying:
…the trust in training data for AI solutions is very high, which in turn reflects the robust infrastructure and processes that organizations have developed over the years to collect continuous telemetry from all parts of the quality engineering process.
I’m less than convinced this is the reason for such confidence and it feels to me like organizations want to feel confident but have little evidence to back up that confidence. I really hope I’m wrong about that, since AI solutions are clearly being seen as useful ways to drive significant decisions, in particular around testing.
The next question is where the reality of AI usage is revealed:
The use cases seem very poorly thought out, though. For example, does performance testing belong in “Performance testing or Test prioritization” or “Performance testing/engineering”? And why would performance testing be lumped together with test prioritization when, to me at least, they’re such different use cases.
I’ll wrap up my observations on this AI section with this data:
I’m suspicious that all of these statements get almost the same level of agreement.
Quality ecosystem
This section (which is similar in content to what was known as “Quality infrastructure testing and provisioning” in the previous report) kicks off by looking at “cloud testing”:
…82% of the survey respondents highlighted cloud testing as mandatory for applications on cloud. This highlights a positive and decisive shift in the testing strategy that organizations are taking on cloud and infrastructure testing. It also demonstrates how important it is to test cloud-related features for functional and non-functional aspects of applications. This change in thinking is a result of organizations realizing that movement to cloud alone does not make the system available and reliable.
The authors consider this data to be very positive, but my initial thought was why this number wouldn’t be 100%?! If your app is in/on the cloud, where else would you test it?
The rest of this section was more cloud stuff, SRE, chaos engineering, etc. and I didn’t find anything noteworthy here.
Digital core reliability
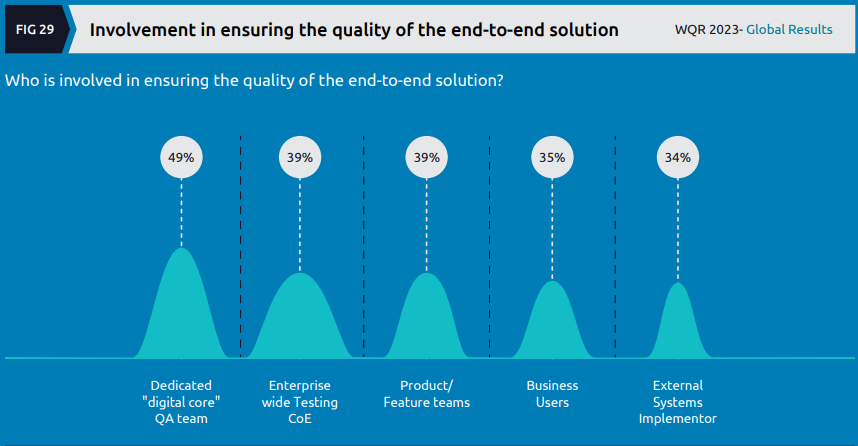
In this section of the report (which had no obvious corresponding section in last year’s report), the focus is on foundational digital (“core”) technology and how QE manages it. In terms of “ensuring quality”:
About half of the respondents say that a dedicated QA team is responsible for “ensuring the quality” but there’s also a high percentage still using CoEs or having testers embedded into product/feature teams according to this data.
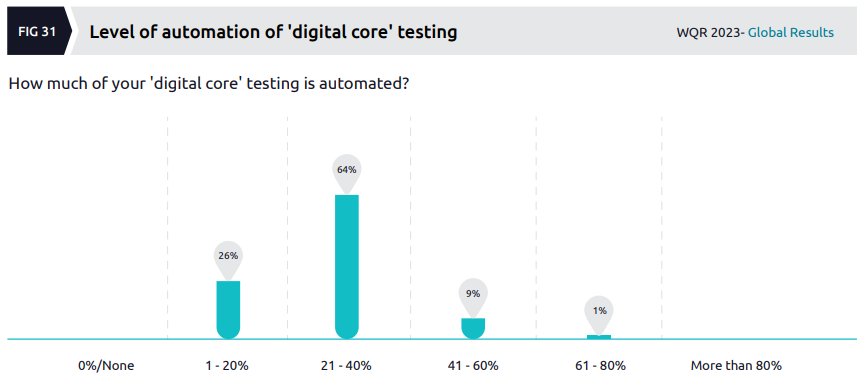
Turning to automation specifically for digital core testing:
The authors go on to discuss an “enigma” around the low level of automation revealed by this data (emphasis is mine):
This clearly is due to the same top challenges around testing digital core solutions – the complexity of the environment owing to the mix of tools, dependencies related to environment and data availability. When it is hard to test, it is even harder to automate.
There’s also another contradiction we need to address – while 31% of organizations feel the pressure to keep up with the pace of development teams developing digital core solutions, 69% of organizations do not feel the pressure. With <40% of automation coverage and digital core solutions becoming more SaaS and less customized, it is a bit of an enigma to unravel. Why don’t organizations feel the pressure to keep up? Is that because they have large QA teams rushing to complete all testing manually? Or are teams stressed by the number and frequency of code drops coming in for testing?
It’s good to see the authors acknowledging that the data is contradictory in this area. There are other possible causes of this “enigma”. Maybe the respondents didn’t answer honestly (or, more generously, misunderstood what they were being asked in some of the survey questions). Maybe they don’t feel the pressure to keep up because they’ve lowered their bar in terms of what they test (per the previous commentary on the “increasing tolerance for defects”).
The following is one of the more sensible suggestions in the entire report:
When it comes to test automation, replicating what functional testers do manually step by step through a tool might not be the best possible approach. Trying to break the end-to-end tests into more manageable pieces with a level of contract testing could be a more sustainable approach for building automated tests.
Wrapping up this section, the focus turns to skills required by testers when testing “digital core”:
The top answer was “Quality Assurance”, is that a testing skillset? It seems awfully broad in answer to the question, in any case. The report’s tendency for confirmation bias rears its ugly head again, with the authors making their own judgements that are unsupported by the data (emphasis is mine):
When we looked at the data, quality assurance skills were rated as the most important skillset over domain or platform skills required for testing digital core solutions. This datapoint feels like bit of an outlier when compared to two other datapoints – 35% of organizations still utilize business users in validating digital core solutions and 33% of organizations pointed to gaps in domain expertise as a challenge to overcome when testing digital core solutions. The truth is while solid testing and quality assurance skills are sought after due to the nature of digital core solutions, domain expertise remains invaluable.
Intelligent product testing
This section (again not obviously close to the content of a section from last year’s report) looks to answer this bizarre question:
What really goes into creating the perfect intelligent product testing system ecosystem?
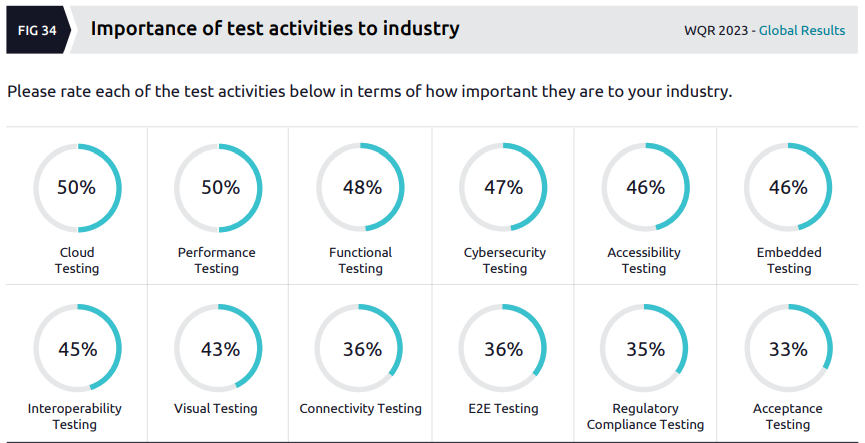
The first data in this section refers to different test activities and how important they are considered to be:
The presentation of this data doesn’t make sense to me, since the respondents were asked to rate the importance of various activities while the results are expressed as percentages. Most of the test activities get very similar ratings anyway, with the authors noting that 36% seems low for “E2E Testing”:
..we were surprised to learn that only 36% thought end-to-end (E2E) testing was necessary. It has been established that the value of connected products is distributed throughout the entire chain, and its resilience depends on the weakest link in the chain, and yet, the overall value of E2E testing has not been fully recognized. One reason we suspect could be that it requires significant investment in test benches, hardware, and cloud infrastructure for E2E testing.
Note how the analysis of the data changes again here – they refer to the necessity of a test activity (E2E testing in this case), not a rating of its importance. I had to chuckle at their conclusion here, which essentially says “E2E testing is too hard so we don’t do it”.
I see no compelling evidence in the report’s data to support the opening claim in the following:
One of the significant trends observed in the WQR 2023 survey is the expectation for improving the test definition. The increasing complexity of products, along with hyper-personalization to create a unique user experience, necessitates passing millions of test cases to achieve the perfect user experience. Realistically speaking, it’s not possible to determine all possible combinations.
The next question has the same rating vs. percentage data issue as the one discussed above, but somewhat supports their claim I suppose:
I again don’t see the evidence to support the following statement (nor do I agree with it, based on my experience):
For product testers, the latest findings suggest that automation toolchain skills and programming languages are now considered mainstream and no longer considered core competencies.
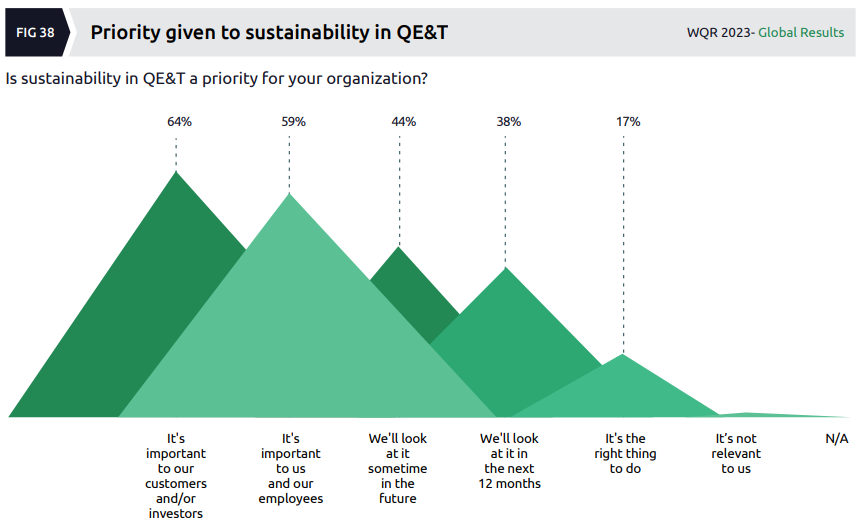
Quality & sustainability
It’s good to see some focus on sustainability in the IT industry, especially when “reports show that data centers and cloud contribute more to greenhouse emissions than the aviation sector”.
This section of the report looks specifically at the role that “quality engineering play in reducing the environmental impact of IT programs and systems”, which seems a little odd to me. I don’t really understand how anyone could answer the following question (and what it even means to do so):
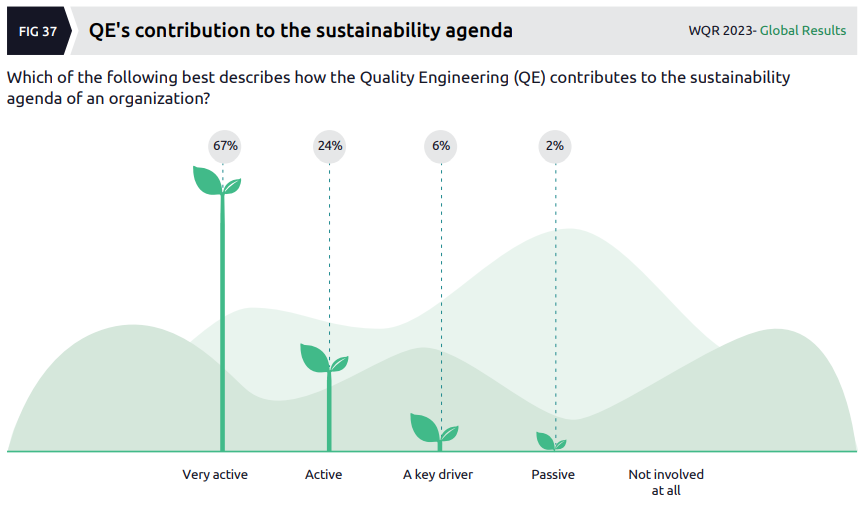
Although the data in this next chart doesn’t excite me, I had to include it here as it takes the gong (amongst a lot of competition) for the worst way of presenting data in the report:
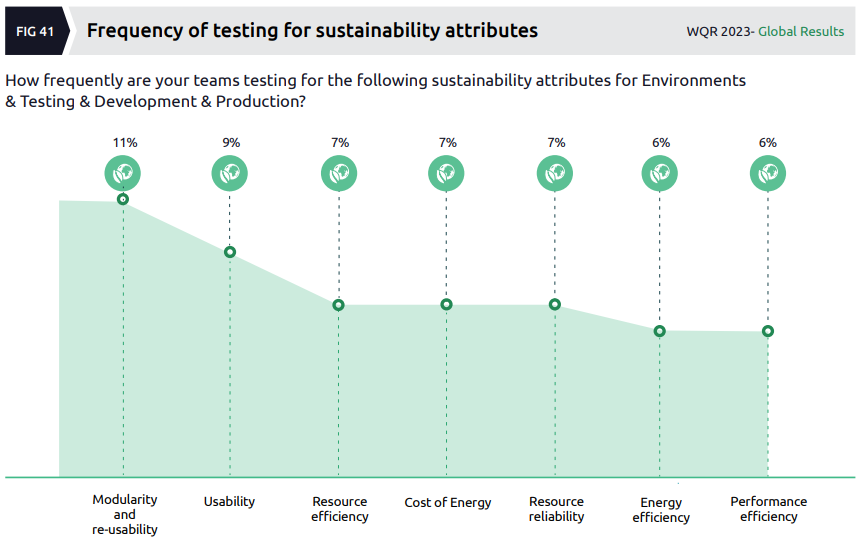
The final chart I’ll share from this section of the report again suffers from a data issue, in that the question it relates to (which itself seems poorly posed and too broad) is one of frequency while the data is shown as a percentage (of what?):
Perhaps I’m reading this wrong, but it seems that almost none of the organizations surveyed are really doing very much to test for sustainability (which is exactly what I’d expect).
Sector analysis (p60-85)
As usual, I didn’t find the sector analysis to be as interesting as the trends section. The authors identify the same eight sectors as the previous year’s report, viz.
Automotive
Consumer products, retail and distribution
Energy, utilities, natural resources and chemicals
Financial services
Healthcare and life sciences
Manufacturing
Public sector
Technology, media and telecoms
Last year’s report provided the same four metrics for each sector but this year a different selection of metrics was presented by way of summary for each sector. A selection of some of the more surprising metrics follows.
In the Consumer sector, 50% of organizations say only 1%-25% of their organizations have adopted Quality Engineering.
In the Consumer sector, 76% of organizations are using traditional testing centres of excellence to support agile projects
In the Financial Services sector, 75% of respondents said they are using or plan to use advanced automation solutions like No Code/ Low Code or AI based automation frameworks.
In the Financial Services sector, 82% of organizations support agile projects through a traditional Testing Center of Excellence.
In Healthcare, 81% of organizations have confidence in the accuracy of data used to train AI platforms.
In the Public sector, 60% of organizations said the top-most issue in agile adoption was lack of time to test.
Geography-specific reports
The main World Quality Report was supplemented by a number of short reports for specific locales. I only reviewed the Australia/New Zealand one and didn’t find much of interest there, with the focus of course being on AI, leading the authors to suggest:
We think that prompt engineering skills are the need of the hour from a technical perspective.
I published my first software testing book, “An Exploration of Testers”, back in 2020.One of my intentions with this project was to generate some funds to give back to the testing community (with 100% of all proceeds I receive from book sales being returned to the community).
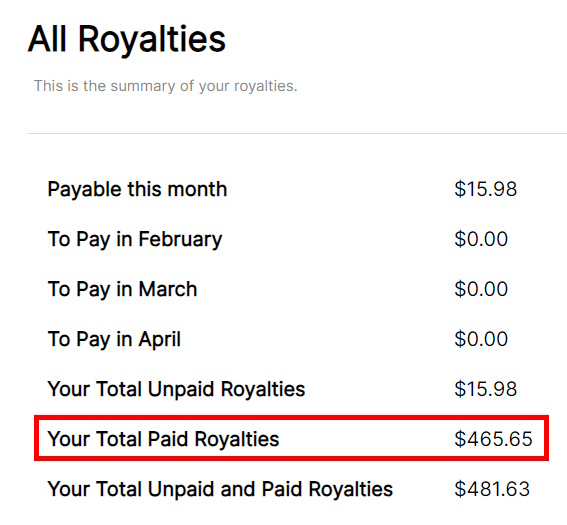
I’m pleased to have made my second donation as a result of sales so far, based on royalties for the book in LeanPub to date:
(Note that my first donation covered the first US$230.93 of sales.)
I’ve now donated a further US$234.72 (and covered their processing fees) to the Association for Software Testing for use in their excellent Grant Program. I’m hopeful that these funds will be used by meetup and peer conference organizers in the future.
I will make further donations of royalties received from book sales not covered by these first two donations.
“An Exploration of Testers” is available for purchase via LeanPub and also comes as one of the benefits of AST membership. My thanks to all of the contributors so far for making the book a reality and also to those who’ve purchased a copy, without whom these valuable donations to the AST would be possible. I’m looking for additional contributions to the book to form a third edition, so please let me know if you’d like to contribute (or have suggestions as to who would make for great contributors!).
It’s time to take the opportunity to review my 2023, a year that has flown by.
Vital statistics
I only published 10 blog posts this year, so didn’t meet my personal target cadence of a post every month. I still enjoy blogging but just haven’t had as many triggers to create posts as in previous years for some reason. My limited activity has probably contributed to the drop in my blog traffic, down by about 40% compared to 2022. Traffic was much heavier during the first quarter than for the rest of the year, reflecting a string of public testing presentations during this time.
One of the most popular posts each year is my critique of the World Quality Report (which I published for the 2020, 2021 and 2022 reports). I missed the recent release of the 2023-24 report, so maybe I’ll get to wading through the latest version early in 2024 and posting my findings as usual!
I’m still on Twitter/X and closed out the year with about 1,250 followers on Twitter, up slightly from last year. I wonder how many testers are still around on this platform and I note that I’m seeing more engagement with my posts on LinkedIn than X now.
Work life
I’ve spent the year working part-time for SSW in my role as Test Practice Lead, the last eight months or so of which have been for a government agency. As my first exposure to government work, it’s been great with an excellent culture and friendly & welcoming colleagues. I’m looking forward to continuing to add value in this role during 2024.
In my own business, Dr Lee Consulting, I’ve focused on my Mentoring offering and have found one-on-one mentoring very rewarding. I find it to be a great learning experience as well as a good opportunity to pass on at least some of what I’ve learned along the way during 25 years in the IT industry. I’m keen to do more in this area, so please let me know if you or your colleagues might be interested in working together. I also launched a new offering, my Second Pair of Eyes service, but have yet to see any traction for it – again, I’d appreciate any leads to kick start this offering.
Testing-related events
I didn’t attend any virtual or in-person testing conferences during 2023, but I did three virtual presentations in the first few months of the year.
First up was an Association for Software Testing (AST) webinar as part of their “Steel Yourselves” series. The idea behind this series is to make the case for a testing idea/concept/approach that you strongly disagree with and I was tasked with defending the need for a testing phase in my session, “Shift Nowhere: A Testing Phase FTW”! I blogged about this experience and you can watch my stab at this difficult task in the second half of the following YouTube video:
I took part in my first “Ask Me Anything” thanks to a webinar by The Test Tribe in which I fielded questions about Exploratory Testing for an hour! This was something new for me and I found it quite challenging, but also enjoyable. I blogged about doing this AMA and a recording of the webinar is on YouTube:
I was pleased to be invited to speak for the Sydney Testers meetup group and I presented a brand new talk, “Lessons Learned in Software Testing” (a deliberate play on the awesome book with the same title) in which I offered a few (potentially contrarian!) lessons I’ve taken away from my long stint in the software testing industry. Thanks to Paul Maxwell-Walters for the invite and it’s great to see Sydney Testers continuing as a large testing community in Australia.
I blogged about my experience of giving this presentation and it was also recorded in full (my talk starts at 32 minutes into the following YouTube video):
I was once again invited to act as a peer advisor for one of Michael Bolton’s virtual “RST Explored” classes running in the Australian timezone. I enjoyed acting in this role back in 2021 and my 2022 experience was great too. I still feel that RST has incredible value and it’s so much more accessible in the virtual format (representing amazing value for money, in my opinion).
Testing books
I made solid progress on the free AST e-book, Navigating the World as a Context-Driven Tester. This book provides responses to common questions and statements about testing from a context-driven perspective, with its content being crowdsourced from the membership of the AST and the broader testing community. I added a further 7 responses in 2023 (bringing the total to 23) and it was good to see a number of new contributors through the year. I will continue to ask for contributions about once a month in 2024. The book is available from the AST’s GitHub.
I failed to publish an updated version of my book An Exploration of Testers during 2023, but hope to do so in 2024. I remain open to additional contributions to this book, so please contact me if you’re interested in telling your story via the answers to the questions posed in the book – and remember that all proceeds from sales of this e-book go to the Association for Software Testing’s excellent Grants program (with another donation from recent sales coming early in 2024).
Reading
My strong reading habit continued during 2023, thanks to the great service from Geelong Regional Libraries. For the first time in many years, I added some fiction into the mix and thoroughly enjoyed doing so. Of the 30-odd books I read this year, the most impactful was From Strength to Strength by Arthur Brooks, while the most engaging fiction came from Hugh Howey’s “Silo” series.
My reading is detailed below (with links to my tweets or blog posts on each of them):
I’ve continued to volunteer with the UK’s Vegan Society both as a proofreader and also contributing to their web research efforts. I didn’t tackle many proofreading jobs this year, focusing more on a number of web projects.
I came up with recommendations for changes to the website’s “About Us” page after reviewing many other sites to define what a modern layout and content should look like for the page. I also undertook the mammoth task of reviewing the “Statistics” pages to identify older stats that should be removed as well as researching newer ones to replace them.
The Society is in the process of building a completely new website and I’ve been heavily involved in testing it. It’s been fun to get my hands dirty with some real testing again and it’ll be great to see the new site going live soon!
Outside of my proofreading and web research work, I’ve also written a couple of blog posts, the first was on vegan Christmas desserts and the second on aquafaba! The audience and style are completely different when writing for the Vegan Society so, as a writer, I’m enjoying this challenge and hoping to pen some more blogs for them in 2024.
Working with The Vegan Society is really enjoyable and they handle volunteers very kindly. It was lovely to receive a “thank you” gift of a sponsorship of “Brucey the goose” at Good Heart Animal Sanctuary in recognition of my efforts this year.
In closing
I remain grateful for the attention & support from the readers of my blog and also my followers on other platforms. I wish you all a Happy New Year and I hope you enjoy my posts and other contributions to the testing community to come through 2024.
While I have no confirmed public appearances in 2024 yet, I’m sure I’ll be out and about somewhere either virtually or in-person so I’ll “see you” around…
I’m used to seeing my feeds (especially LinkedIn) full of “automate everything” nonsense posts in the field of testing. This stream of misinformation seems to be flowing ever faster as more and more folks jump on the AI bandwagon, whether it’s in “testing tools leveraging AI” or the use of LLM models such as ChatGPT to reduce or remove the need for those pesky human elements of testing.
The Australian Securities and Investments Commission (ASIC) has listed “intelligently automate everything we do” as one of five principles of its internal digital strategy, according to documents obtained by this masthead [The Age] under freedom of information laws.
One of ASIC’s key roles is to investigate reports of serious misconduct and its existing use of automation in this regard has already been criticized:
The use of automation within ASIC garnered controversy earlier this year after liquidators claimed reports of serious corporate misconduct were dismissed in as little as 38 seconds, allowing thousands of company directors to avoid scrutiny over five years.
The article goes on to quote Helen Bird, part of ASIC’s corporate governance panel:
Bird … warned the technology behind automation and AI was not ready for wide deployment within the regulator.
Bird said it was inevitable that AI would eventually be used across all regulators because of the significant cost-saving opportunities from removing time-consuming manual tasks and reducing or redeploying staff.
It was only a matter of time before “manual” entered the narrative here, just like when reading the automation versus “manual” testing posts littering my feed every day. Despite the problems already identified with trying to automate the difficult task of investigating financial misconduct, in this case the regulator seems intent to go further down the automation and AI path – but maybe we can take solace in the fact that at least they’ll be doing it “intellgently”. Ironically:
Earlier this year, [ASIC chair] Longo warned traders and investment banks against rushing to use artificial intelligence technology. He said inappropriate use of AI could create “unintended consequences” if adopted without proper controls and governance.
I recently read “From Strength to Strength” by Arthur C. Brooks and rarely has a book talked to me as directly as this important effort.
I realized after reading this book that I’ve been a striver for as long as I can remember, pushing myself to achieve and enjoy professional success. I was the star student of mathematics at university and then successfully completed my PhD in mathematics in a little over three years.
My professional career saw me climbing the corporate ladder, ultimately becoming one of six Director-level folks leading up the software development arm of a US$300m+ software business. When my 21-year stint at Quest came to an abrupt and unexpected end, I took some time to reset and ultimately started my own consultancy to continue on with my professional life in testing.
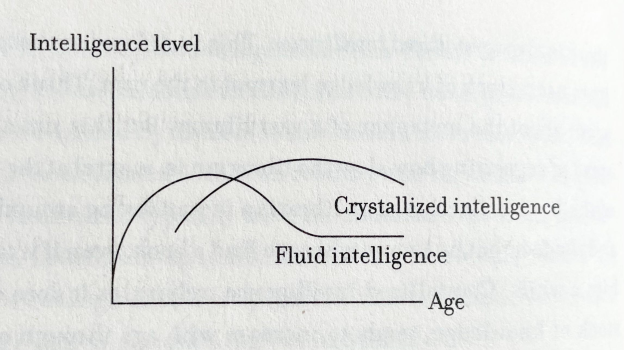
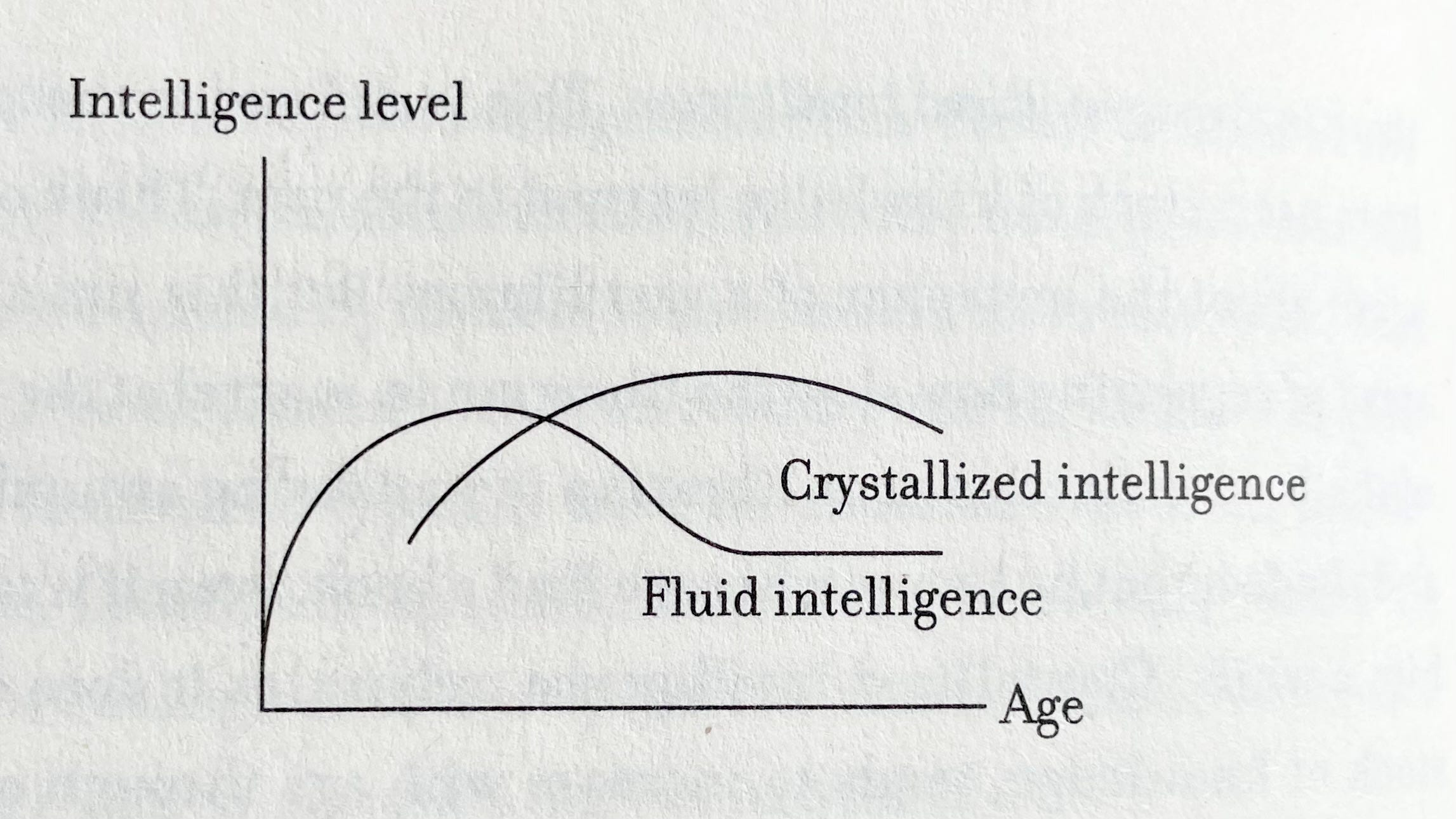
An important idea in the book is the difference between fluid and crystallized intelligence. In essence, fluid intelligence is your ability to process new information, learn and solve problems, while crystallized intelligence is the ability to use a stock of knowledge learned in the past.
This diagram illustrates how these types of intelligence generally change as we age:
Brooks makes this observation, which struck a very strong chord with me:
“If you are experiencing decline in fluid intelligence – and if you are my age, you are – it doesn’t mean you are washed up. It means it is time to jump off the fluid intelligence curve and onto the crystallized intelligence curve. Those who fight against time are trying to bend the old curve instead of getting onto the new one. But it is almost impossible to bend, which is why people are so frustrated, and usually unsuccessful.”
I’ve witnessed older members of the testing community in Melbourne struggling with this as they try to fight against time and stay relevant in ways that really don’t make sense. I’m realizing I’ve naturally been shifting my focus to crystallized intelligence, out of necessity but also it’s where I get more fulfilment.
Brooks makes the point that:
“when you are young, you have raw smarts; when you are old, you have wisdom. When you are young, you can generate lots of facts; when you are old, you know what they mean and how to use them.”
He notes the inevitably of decline but also the hope that shifting perspective can bring with it new and exciting opportunities later in life:
“Almost without fail, you will notice the decline in the fluid intelligence portion. However, there always exists the ability to redesign your career less on innovation and more on instruction as the years pass, thus playing to your strengths with age.”
I recognize that I can no longer keep up with the younger folks in many ways, I have less and less interest in the latest tools and tech, and being on the critical path in day-to-day project work doesn’t bring me joy. But I’m finding my niche in helping to guide folks with my accrued wisdom:
“So what do the young hotshots need? Old people on product teams, old people in marketing, and old people in the C-suite. They need not just whiz-bang ideas but actual wisdom that only comes with years in the school of hard knocks.”
Brooks notes:
“Practiced properly, old people have an edge over younger people, because they have more experience at life and relationships”
and he also quotes the philosopher Marcus Tullius Cicero who:
“…believed three things about older age. First, that it should be dedicated to service, not goofing off. Second, our greatest gift later in life is wisdom, in which learning and thought create a worldview that can enrich others. Third, our natural ability at this point is counsel: mentoring, advising and teaching others, in a way that does not amass worldly rewards of money, power or prestige.”
I’m certainly finding a lot of enjoyment and fulfilment from my mentoring activities, there’s no frustration there and it’s probably a sign of already spending some or most of my time exploiting crystallized intelligence:
“The decline in your fluid intelligence is a sign that it is time not to rage, which just doubles down on your unsatisfying attachments and leads to frustration. Rather, it is a time to scale up your crystallized intelligence, use your wisdom, and share it with others.”
I think my mindfulness practice over the last few years has helped here too (and is also mentioned by Brooks in his book) and I’ve become much more comfortable showing vulnerability. I have no issue with saying “I don’t know” and feel no need for pretence – and have found in doing so that people generally seem to see me as more credible, rather than less:
“To share your weakness without caring what others think, is a kind of superpower”
The cool work of Chip Conley and his Modern Elder Academy gets a well-deserved shout out here too.
This is an important book and especially so for those of us later in our careers as we look for new meaning and ways to find satisfaction from sharing, teaching and so on. It’s a great read and a handy nudge to follow a different path – not better or worse, but one befitting our wisdom and also likely to be more fulfilling. As Brooks notes:
“Get old sharing the things you believe are most important. Excellence is always its own reward, and this is how you can be most excellent as you age”
The Sydney Testers meetup has been Australia’s largest testing meetup for many years and I was more than happy to help when organizer, Paul Maxwell-Walters, was looking for speakers.
I already had a conference talk “in the can” due to being unable to present at the Melbourne Testing Talks conference in 2022, so my preparation only consisted of some minor updates to the slide deck and a practice run to nail down the slide transitions and timing.
The meetup took place on the evening of 12th April and I would be second up (presenting virtually over Zoom), following Ashley Graf‘s half-hour talk on “50 questions to faster onboarding (as a QA)”. A decent crowd formed during the first 30-45 minutes of the session and I took the virtual stage at just after 6.30pm.
My talk was titled “Lessons Learned in Software Testing” and I shared six lessons I’ve learned during my twenty-odd years in the testing industry. I guess some of my opinions and lessons are a little contrarian, but I’m OK with that as much of what I see presented as consensus around testing (especially on platforms like LinkedIn) doesn’t reflect my lived experience in this industry. If you want to know the six lessons that I shared, you’ll need to watch all 45 minutes of my presentation!
Thanks to Paul for the opportunity to present to the Sydney Testers audience and also for the interesting questions during the Q&A afterwards.
A recording of both talks from this meetup (as well as the Q&A) is available on YouTube (my talk starts at 32 minutes into this recording):
I recently read “Meltdown” by Chris Clearfield & András Tilcsik. It was an engaging and enjoyable read, illustrated by many excellent real-world examples of failure. As is often the case, I found that much of the book’s content resonated closely with testing and I’ll share four of the more obvious cases in this blog post, viz:
An indicator light in the control room led operators to believe that the valve was closed. But in reality, the light showed only that the valve had been told to close, not that it had closed. And there were no instruments directly showing the water level in the core so operators relied on a different measurement: the water level in a part of the system called the pressurizer. But as water escaped through the stuck-open valve, water in the pressurizer appeared to be rising even as it was falling in the core. So the operators assumed that there was too much water, when in fact they had the opposite problem. When an emergency cooling system turned on automatically and forced water into the core, they all but shut it off. The core began to melt.
The operators knew something was wrong, but they didn’t know what, and it took them hours to figure out that water was being lost. The avalanche of alarms was unnerving. With all the sirens, klaxon horns, and flashing lights, it was hard to tell trivial warnings from vital alarms.
Meltdown, p18 (emphasis is mine)
I often see a similar problem with the results reported from large so-called “automated test suites”. As such suites get more and more tests added to them over time (it’s rare for me to see folks removing tests, it’s seen as heresy to do so even if those tests may well be redundant), the number of failing tests tends to increase and normalization of test failure sets in. Amongst the many failures, there could be important problems but the emergent noise makes it increasingly hard to pick those out.
I often question the value of such suites (i.e. those that have multiple failed tests on every run) but there still seems to be a preference for “coverage” (meaning “more tests”, not actually more coverage) over stability. Suites of tests that tell you nothing different whether they all pass or some fail are to me pointless and pure waste.
So, are you in control of your automated test suites and what are they really telling you? Are they in fact misleading you about the state of your product?
2. Systems and complexity
The book focuses on complex systems and how they are different when it comes to diagnosing problems and predicting failures. On this:
Here was one of the worst nuclear accidents in history, but it couldn’t be blamed on obvious human errors or a big external shock. It somehow just emerged from small mishaps that came together in a weird way.
In Perrow’s view, the accident was not a freak occurrence, but a fundamental feature of the nuclear power plant as a system. The failure was driven by the connections between different parts, rather than the parts themselves. The moisture that got into the air system wouldn’t have been a problem on its own. But through its connection to pumps and the steam generator, a host of valves, and the reactor, it had a big impact.
For years, Perrow and his team of students trudged through the details of hundreds of accidents, from airplane crashes to chemical plant explosions. And the same pattern showed up over and over again. Different parts of a system unexpectedly interacted with one another, small failures combined in unanticipated ways, and people didn’t understand what was happening.
Perrow’s theory was that two factors make systems susceptible to these kinds of failures. If we understand those factors, we can figure out which systems are most vulnerable.
The first factor has to do with how the different parts of the system interact with one another. Some systems are linear: they are like an assembly line in a car factory where things proceed through an easily predictable sequence. Each car goes from the first station to the second to the third and so on, with different parts installed at each step. And if a station breaks down, it be immediately obvious which one failed. It’s also clear What the consequences will be: cars won’t reach the next station and might pile up at the previous one. In systems like these, the different parts interact in mostly visible and predictable ways.
Other systems, like nuclear power plants, are more complex: their parts are more likely to interact in hidden and unexpected ways. Complex systems are more like an elaborate web than an assembly line. Many of their parts are intricately linked and can easily affect one another. Even seemingly unrelated parts might be connected indirectly, and some subsystems are linked to many parts of the system. So when something goes wrong, problems pop up everywhere, and it’s hard figure out what’s going on.
In a complex system, we can’t go in to take a look at what’s happening in the belly of the beast. We need to rely on indirect indicators to assess most situations. In a nuclear power plant, for example, we can’t just send someone to see what’s happening in the core. We need to piece together a full picture from small slivers – pressure indications, water flow measurements, and the like. We see some things but not everything. So our diagnoses can easily turn out to be wrong.
Perrow argued something similar: we simply can’t understand enough about complex systems to predict all the possible consequences of even a small failure.
Meltdown, p22-24 (emphasis is mine)
I think this discussion of the reality of failure in complex systems makes it clear that trying to rigidly script out tests to be performed against such systems is unlikely to help us reveal these potential failures. Some of these problems are emergent from the “elaborate web” and so our approach to testing these systems needs to be flexible and experimental enough to navigate this web with some degree of effectiveness.
It also makes clear that skills in risk analysis are very important in testing complex systems (see also point 4 in this blog post) and that critical thinking is essential.
3. Safety systems become a cause of failure
On safety systems:
Charles Perrow once wrote that “safety systems are the biggest single source of catastrophic failure in complex, tightly coupled systems.” He was referring to nuclear power plants, chemical refineries, and airplanes. But he could have been analyzing the Oscars. Without the extra envelopes, the Oscars fiasco would have never happened.
DESPITE PERROW’S WARNING, safety features have an obvious allure. They prevent some foreseeable errors, so it’s tempting to use as many of them as possible. But safety features themselves become part of the system – and that adds complexity. As complexity grows, we’re more likely to encounter failure from unexpected sources.
Meltdown, p85 (Oscars fiasco link added, emphasis is mine)
Some years ago, I owned a BMW and, it turns out, it was packed full of sensors designed to detect all manner of problems. I only found about some of them when they started to go wrong – and doing so much more frequently than the underlying problems they were meant to detect. Sensor failure was becoming an everyday event, while the car generally ran fine. I solved the problem by selling the car.
I’ve often pitched good automation as a way to help development (not testing) move faster with more safety. Putting in place solid automated checks at various different levels can provide excellent change detection, allowing mis-steps during development to be caught soon after they are introduced. But the author’s point is well made – we run the risk of adding so many automated checks (“safety features”) that they themselves become the more likely source of failure – and then we’re back to point 1 of this post!
I’ve also seen similar issues with adding excessive amounts of monitoring and logging, especially in cloud-based systems, “just because we can”. Not only can these give rise to bill shock, but they also become potential sources of failure in themselves and thereby start to erode the benefits they were designed to bring in diagnosing failures with the system itself.
4. The value of pre-mortems
The “premortem” comes up in this book and I welcomed the handy reminder of the concept. The idea is simple and feels like it would work well from a testing perspective:
Of course, it’s easy to be smart in hindsight. The rearview mirror, as Warren Buffett once supposedly said, is always clearer than the windshield. And hindsight always comes too late – or so it seems. But what if there was a way to harness the power of hindsight before a meltdown happened? What if we could benefit from hindsight in advance?
This question was based on a clever method called the premortem. Here’s Gary Klein, the researcher who invented it:
If a project goes poorly, there will be a lessons-learned session that looks at what went wrong and why the project failed – like a medical postmortem. Why don’t we do that up front? Before a project starts, we should say, “We’re looking in a crystal ball, and this project has failed; it’s a fiasco. Now, everybody, take minutes and write down all the reasons why you think the project failed.”
Then everyone announces what they came up with – and they suggest solutions to the risks on the group’s collective list.
The premortem method is based on something psychologists call prospective hindsight – hindsight that comes from imagining that an event has already occurred. A landmark 1989 study showed that prospective hindsight boosts our ability to identify reasons why an outcome might occur. When research subjects used prospective hindsight, they came up with many more reasons – and those reasons tended to be more concrete and precise – than when they didn’t imagine the outcome. It’s a trick that makes hindsight work for us, not against us.
If an outcome is certain, we come up with more concrete explanations for it – and that’s the tendency the premortem exploits. It reframes how we think about causes, even if we just imagine the outcome. And the premortem also affects our motivation. “The logic is that instead of showing people that you are smart because you can come up with a good plan, you show you’re smart by thinking of insightful reasons this project might go south,” says Gary Klein. “The whole dynamic changes from trying to avoid anything that might disrupt harmony to trying to surface potential problems.”
Meltdown, p114-118
I’ve facilitated risk analysis workshops and found them to be useful in generating a bunch of diverse ideas about what might go wrong (whether that be for an individual story, a feature or even a whole release). The premortem idea could be used to drive these workshops slightly differently, by asking the participants to imagine that a bad outcome has already occurred and then coming up with ways that could have happened. This might result in the benefit of prospective hindsight as mentioned above. I think this is worth a try and will look for an opportunity to give it a go.
In conclusion
I really enjoyed reading “Meltdown” and it gave me plenty of food for thought from a testing perspective. I hope the few examples I’ve written about in this post are of interest to my testing audience!
I took part in my first “Ask Me Anything” session on 22nd March, answering questions on the topic of “Exploratory Testing” as part of the AMA series organized by The Test Tribe.
Presenting an AMA was a different experience in terms of preparation compared to a more traditional slide-driven talk. I didn’t need to prepare very much, although I made sure to refamiliarize myself with the ET definitions I make use of and some of the most helpful resources so they’d all be front of mind if and when I needed them to answer questions arising during the AMA.
The live event was run using Airmeet.com and I successfully connected about ten minutes before the start of the AMA. The system was easy to use and it was good to spend a few minutes chatting with my host, Sandeep Garg, to go over the nuts and bolts of how the session would be facilitated.
We kicked off a few minutes after the scheduled start time and Sandeep opened with a couple of questions while the attendees started to submit their questions into Airmeet.
The audience provided lots of great questions and we managed to get through them all, in just over an hour. I appreciated the wide-ranging questions which demonstrated a spectrum of existing understanding about exploratory testing. There is so much poor quality content on this topic that it’s unsurprising many testers are confused. I hope my small contribution via this AMA helped to dispel some myths around exploratory testing and inspired some testers to take it more seriously and start to see the benefits of more exploratory approaches in their day-to-day testing work.
Thanks to The Test Tribe for organizing and promoting this AMA, giving me my first opportunity of presenting in this format. Thanks also to the participants for their many questions, I hope I provided useful responses based on my experience of adopting an exploratory approach to testing over the last 15 years or so!